Fundamentals of System Integration


Abstract
- A vendor-agnostic article that discusses the fundamentals of system integration and commonly used building blocks
- Discusses the specific requirements of a system integration solution and what differentiates it from other software development
- Describes the publish-subscribe pattern and why it is fundamental to any system integration solution
- Examines the difference between an asynchronous and a synchronous system integration solution
- Walks through a number of common system integration patterns
Understanding the fundamentals of system integration is crucial for developing effective integration solutions.
Background
Transferring data between destinations A and B is a common practice for nearly every company with more than a few IT systems in place.
However, there are many ways to achieve this.
System integration is often grouped with other software development tasks, focusing on transferring and transforming data between components using current technologies and architecture. However, it is important to understand that system integration solutions have unique requirements that are not typically found in other types of software development.
When doing this work with a more specific approach, it is often referred to as system integration.
Let's examine the core requirements for a system integration solution.
Requirements for a system integration solution
We divide the requirements into Level 1 and Level 2 requirements and a section we will refer to as additional expectations.
Level 1 requirements
These are the essential requirements needed in all system integration solutions. They ensure that data integration is reliable and efficient, meeting the diverse needs of various systems.
-
Guaranteed delivery
It is crucial that no data is lost during the integration process. We must guarantee the delivery of data to all destination systems under all circumstances. -
Data transformation
Data often arrives in one format and needs to be delivered in another. Any integration solution must have the ability to transform data into different formats. -
Adaptation to different protocols
Similar to data transformation, an integration solution must be able to handle various technical protocols. Data may be received over one protocol but needs to be sent using another.
Level 2 requirements
These capabilities are expected in more advanced system integration solutions.
-
Routing
As data is received, it is often required that the integration solution can route it to multiple destinations, usually based on the type of data received.For example, an incoming order should always be sent to Destination A, but if the order value exceeds a specific amount, it should also be sent to Destination B. This is commonly referred to as message-based routing.
-
Workflow/Orchestration
In addition to routing, it is common for integration solutions to handle more complex workflows based on business requirements.For example, data may need to be sent to a destination while waiting for a response asynchronously. Additionally, different paths may need to be taken in a workflow based on complex conditions in the data.
Additional expectation
-
Streamlined architecture and design
When handling system integrations in an unstructured manner, technical debt can accumulate quickly as solutions are designed and implemented differently. A more structured approach ensures that common design patterns and techniques are used for all data integration.The result is a solution that is much easier to manage and run over time.
-
Shared error handling and monitoring
Committing to a shared error handling and monitoring solution is essential for maintaining the integrity and reliability of the integration processes.
Core patterns
Before we dive into more specific patterns, let's examine some of the core ideas behind them.
Pattern archetypes: Synchronous vs Asynchronous
All integration solutions can be categorized into two main archetypes.
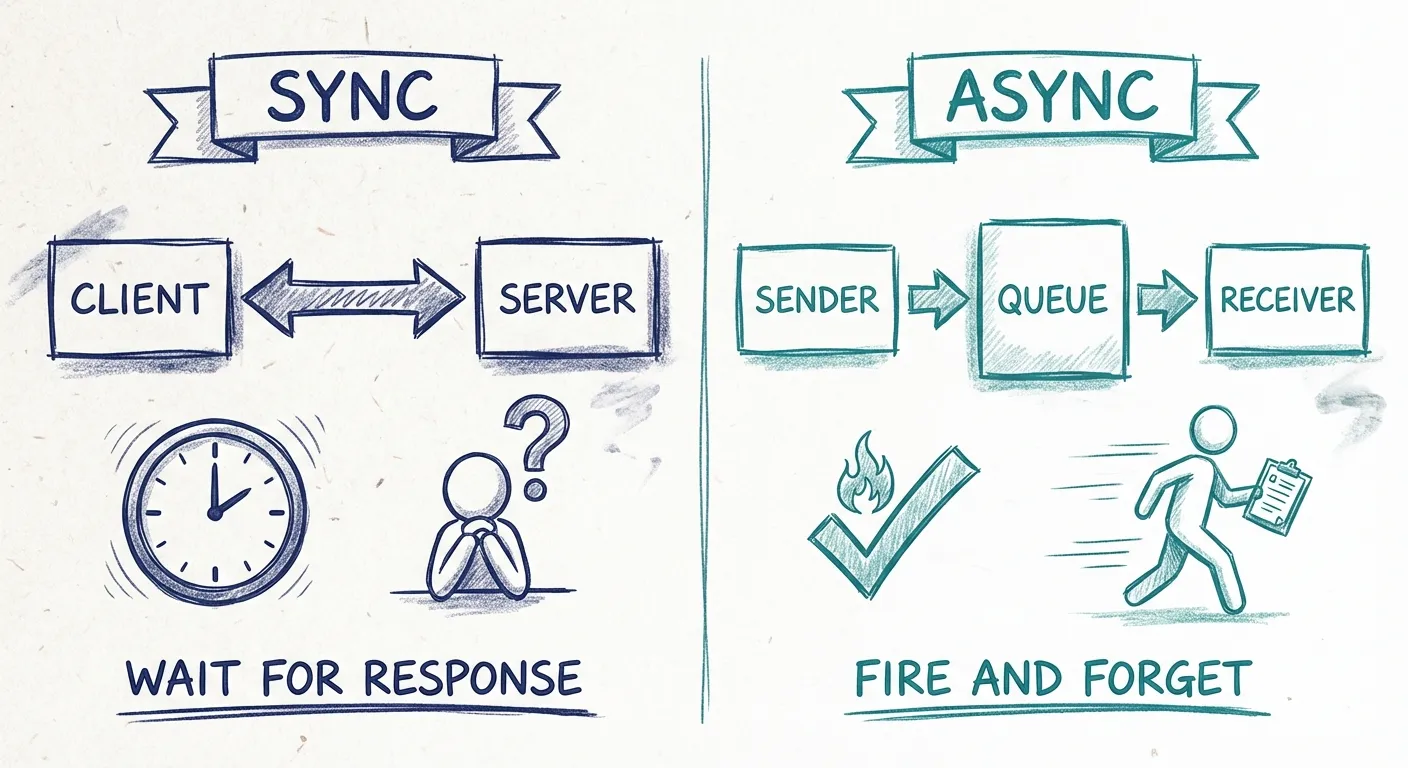
-
Synchronous integration patterns
These patterns involve situations where the sender expects a direct response.For example, when a client requests data, it anticipates receiving that data quickly and displays it to users as soon as possible.
In theory, the patterns could be implemented using several different protocols, but today, these almost always involve HTTP-based request-response APIs.
-
Asynchronous integration patterns
Asynchronous patterns are utilized when the sending system does not expect an immediate response but simply wants to send data.
The publish-subscribe pattern
The publish-subscribe pattern is fundamental to system integration and is a core idea in both queue solutions and integration platforms. It divides components into senders (publishers) and receivers (subscribers).
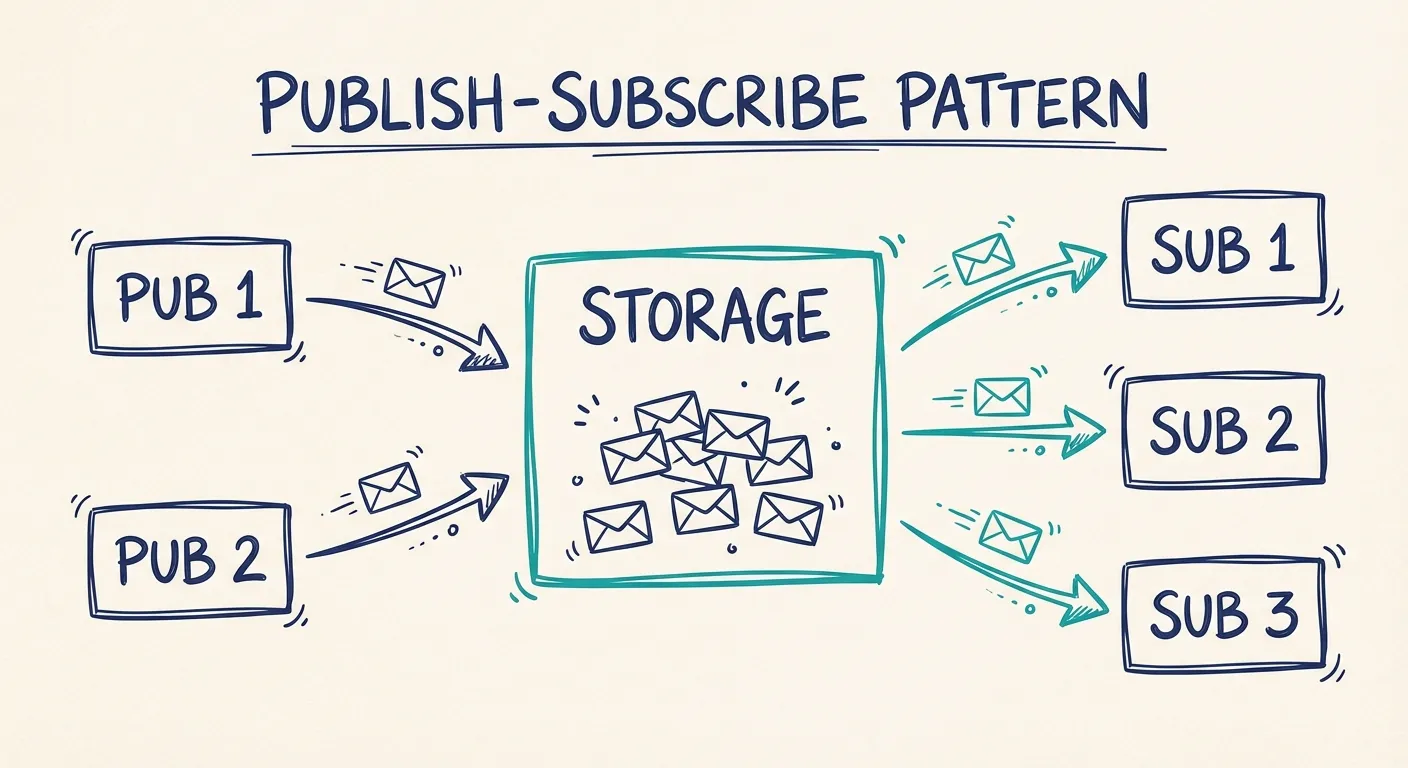
Publishers are responsible solely for sending messages to a storage system, while subscribers focus on reading from that storage.
A typical implementation of the publish-subscribe pattern is a queuing system, but it can very well be implemented using a database or simple storage and custom logic.
The publish-subscribe pattern offers several advantages and meets many of the above-mentioned requirements of an Integration Solution.
-
Decoupling
Publishers and subscribers operate independently, allowing them to evolve separately without impacting each other. -
Asynchronous communication
Subscribers can receive messages without a direct connection to the publishers, enabling robust systems where both can continue functioning even if one side is down. -
Guaranteed delivery
The publish-subscribe pattern ensures that messages are securely stored until all subscribers have received their copy of the message. -
Scalability
Multiple subscribers can listen to messages without affecting the publisher's performance.
As mentioned, the publish-subscribe pattern is fundamental in all system integration patterns. All concrete patterns are more or less an implementation of it or use it part of their solution.
Common integration building blocks
In the patterns, a number of components are referenced. These are the same building blocks that we find in all integration solutions. They can sometimes be custom bespoke components, a library combined into more complex components or part of an off-the-shelf product.
But to fully understand the purpose of each one within the patterns, this article will show them separately.
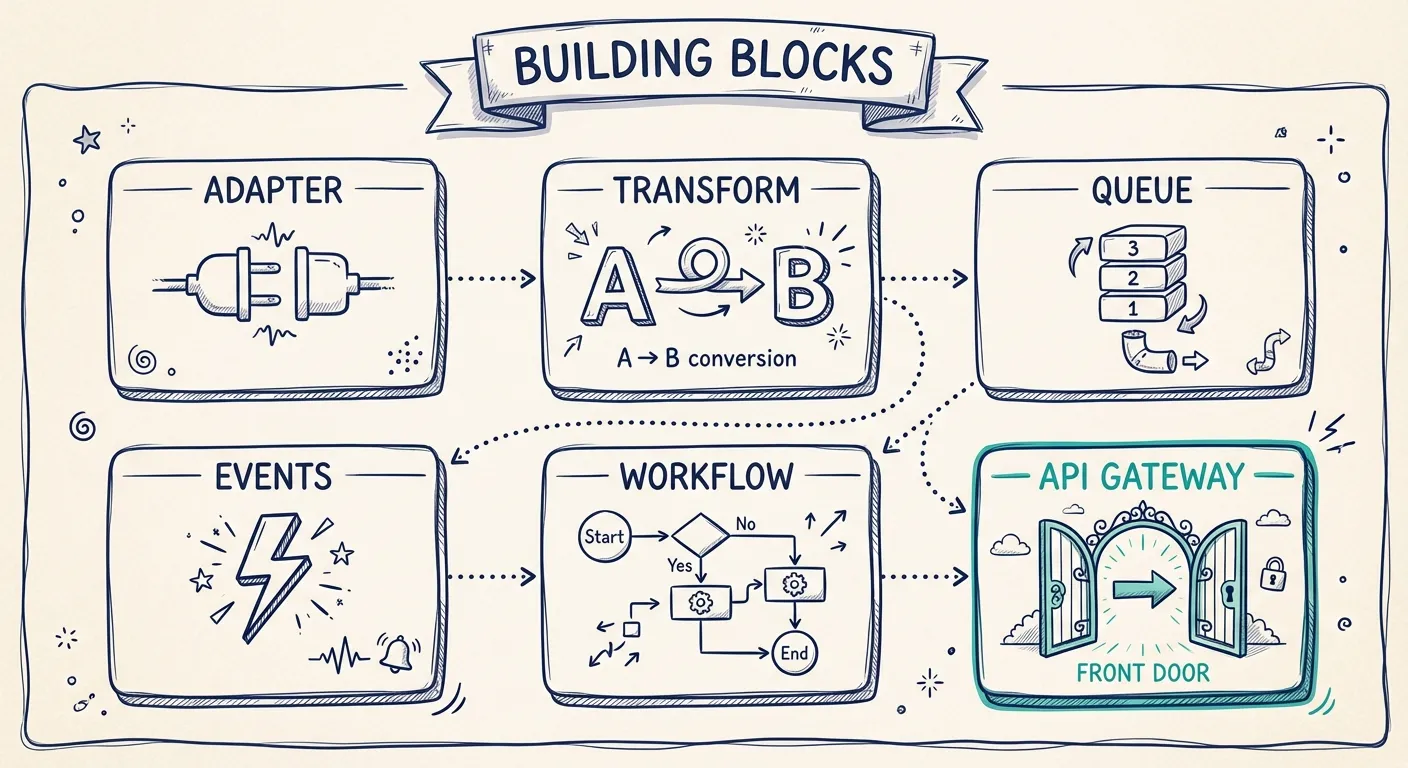
Adapter
An adapter implements the protocol adapter capabilities in a system integration solution.
Handling different protocols is key in a flexible integration solution; we need to be able to send and receive data from systems in everything from HTTP, FTP, SQL, file, database, etcetera.
Transformation (mapping)
Responsible for transforming data between different formats and models (often referred to as mapping data).
It needs to handle format transformation between, for example, XML and JSON, as well as transformation between different data models within the same format.
A typical pattern in integration solutions is to transform incoming using a canonical internal format. A canonical format helps decouple the incoming format's transformation logic to the transformation logic for the format that should be sent to the destination system. A decoupled format makes it possible to handle changes between the incoming and canonical formats without affecting the transformation of all subscribing systems.
Transformations can be implemented using everything from custom code to more specific languages such as Liquid or XSLT.
Queue
A queue is a first-in-first-out structure that a message is published to (enqueued).
Queueing systems have built-in logic to ensure that all subscribers receive their messages. If a subscriber doesn't receive their message within the configured time and retries, it is sent to a dead-letter queue.
Depending on the implementation of the queue, there can be one or several subscribers that dequeues the message. A queue can also implement routing logic and use filters to send specific messages to specific subscribers.
A queue is often an off-the-shelf product and rarely makes sense to implement ourselves. Commonly used solutions are RabbitMQ, Apacke ActiveMQ and Azure Service Bus
Events/Event Manager
An event-driven architecture also relies heavily on the publish-subscribe pattern with the big difference that it does not handle messages; it handles events.
Events are occurrences such as "customer-created" or "invoice-paid" and should adhere to a common format. The CloudEvents specification provides a standardized format for events.
There are several off-the-shelf implementations of products for handling events, but again, they all have characteristics similar to those of a queue system but are optimized for handling event-type messages.
Workflow/orchestration
In more advanced solutions, it is common to have a place for implementing workflow-type logic. An example can be receiving an event and, based on that event, reading messages from a system before sending them to the destination system.
Implementation of workflows and orchestration logic can be done in everything from custom code to more low-code tools like Azure Logic Apps or Zapier.
API Gateway
API Gateways proxies HTTP requests and creates a single entry point for all apps within an organization. This also enables creating APIs that are similar in look and feel, use a common authentication and authorization, and much more.
In the end, it again decouples the frontend APIs that we publish to the customer from the API of the backend publisher - making it possible to make changes in both the backend and the front end without affecting each other.
Examples of well-known API Gateway products are Kong, AWS API Gateway and Azure API Management.
Integration patterns
These patterns are abstractions and simplifications of concrete patterns.
System integration platforms and components often combine these patterns and components into products and more complex components.
But to fully understand and evaluate more complex system integration products and platforms, it's essential to understand the fundamentals.
Pattern 1: Queue-based Asynchronous Publish-Subscribe
Used for sending data when an immediate response is not required. This doesn't mean no response, but it's not expected to be received immediately.
The queue-based Asynchronous publish-subscribe pattern is the most straightforward and used system integration pattern.
Pattern walkthrough
-
Receives data via an
Adaptercomponent Data can be received over multiple protocols. TheAdapteris responsible for handling communication with the receiving system. -
Data is transformed from the received format to a canonical format using a
Transformationcomponent -
Data enqueued in a
Queuecomponent -
Subscribers dequeue data from
Queuecomponent -
Data is transformed from canonical format into sending format using a
Transformationcomponent -
Data sent to the receiving system using an
Adaptercomponent
Pattern 2. Event-based Asynchronous Publish-Subscribe
The event-based asynchronous publish-subscribe pattern is very similar to pattern 1, with the exception of using events instead of messages.
However, in an event-based system integration solution, we must handle an event (such as a "created invoice") and the actual invoice message.
One of the main advantages of event-based architecture over message-based architecture is efficiency and performance. Instead of constantly polling for new messages using timers and loops, events are better suited to listen for. Using techniques like long-time-pooling and web sockets for listening often makes things faster and saves resources.
Pattern walkthrough
-
An event is revived into an
Event Manager -
Our Custom
Workflowreceives the event -
Reads message from the sending system using an
Adaptercomponent -
Transforms from a sending system format into a canonical format using a
Transformcomponent -
Enqueues message to a
Queue -
Dequeues message from
Queue -
Data is transformed from a received format to a canonical format using a
Transformationcomponent -
Data is transformed from canonical format into sending format using a
Transformationcomponent -
Data is sent to the receiving system using an
Adaptercomponent
Pattern 3. Synchronous API read service
As mentioned previously, synchronous integration is used when we need to quickly get data to some data consumer in a request-response-like situation.
However, retrieving data rapidly and reliably from backend systems is often not possible. It is also not always advisable, as it can put unnecessary strain on the backend systems and utilize resources that might be needed to handle their core responsibilities.
That is why storing data in a cache-like solution is almost always a good idea and then serving it to the consumer from there.
However, we need to handle the data changes in the source system. To do this, we combine this pattern with one of the previous asynchronous patterns. This part of the solution is responsible for connecting to the source system and updating the cache-like data source we use in this pattern as soon as data changes.
Pattern walkthrough
-
Consumer requesting via an
API Gateway -
Transform request format into a canonical format for querying our data source using a
Transformationcomponent This is often a built-in capability in theAPI Gateway, but is shown as a separate component here for clarity. -
Querying the data source using a
Adaptercomponent -
Handle source data changes Using asynchronous pattern 1 or 2 to identify changes in source data and update the data source used for reading.
Addressing the additional expectation
Finally, let's look at how we can address the additional expectations we have on integration solutions when it comes to a streamlined architecture and design and how to handle error and monitoring.
Streamlined architecture and design
One big advantage integration solutions have over more general software development is that integration solutions will be very similar, and it's possible to reuse our patterns and common building blocks.
Therefore, it's essential to take the time to create a clear architecture of how we should implement our solutions. What techniques, patterns, and building blocks should we use, and which ones shouldn't we use.
Decision, platform or no platform
There are several popular integration platforms on the market. These combine all the patterns and building blocks that we look at in this article into one single product.
Examples of platforms are MuleSoft and Boomi.
Choosing a platform for all our integration makes streamlining our architecture much easier, as it will limit our choices in a good way. The big downside is the lock-in effect. It will be much harder to migrate from.
The alternative to using a platform is using smaller building blocks to create our architecture. This approach allows us to combine products such as API Gateways, queues, workflow engines, and other building blocks we have looked at. We are making it much easier to replace specific products as things evolve.
Shared error handling and monitoring
Integration solutions are notoriously complex to monitor. The main reason is that they often span over many components and systems, often both in cloud and on-premise.
Monitoring as part of a platform
As mentioned above, using a platform helps as monitoring is built-in. However, components, such as databases, FTP/SFTP servers, custom code, etcetera, are often part of the integration but are outside the platform and need monitoring.
Further, all the major cloud platforms have their own monitoring solution. But again, more is needed, especially if we have integrations that span both the cloud and our on-premise systems.
Many products try to solve this by offering end-to-end tracing and monitoring. A few examples are Nodinite, New Relic, Dynatrace.
But as more and more frameworks, products, and platforms embrace OpenTelemetry, the future of monitoring looks brighter than ever.
Summary
This article has highlighted the unique requirements of integration projects compared to standard software development, emphasizing the importance of guaranteed delivery, data transformation, and protocol adaptation.
We see how decoupled communication enhances system flexibility by categorizing integration patterns into synchronous and asynchronous types and focusing on the pivotal publish/subscribe model.
Furthermore, recognizing key integration components such as adapters, transformation tools, queues, event managers, orchestration tools, and API gateways is essential for creating scalable and efficient integration strategies.
With these insights, organizations can better navigate the complexities of system integration to achieve seamless connectivity between disparate systems.
You Might Also Like

Mermaid vs PlantUML: Which Diagram as Code Tool Should You Choose?
Mermaid is easier to start and easier to embed in docs. PlantUML is broader, deeper, and stronger for C4-heavy teams. Here is how to choose between them, and when neither is the right long-term answer for architecture docs.

Mermaid Architecture Diagram: When It Works, When It Breaks, and When to Move On
Thinking about using a Mermaid architecture diagram? Mermaid is fast, Git-friendly, and easy to drop into docs. But once systems grow, layout pain, duplication, and drift show up fast. Here is where Mermaid works, where it breaks, and when teams need something more.

Diagram as Code: When Text Wins, When It Doesn't, and What Comes Next
Diagram-as-code promises version control, diffs, and developer workflows. But it also trades visual thinking for syntax overhead. Here's an honest look at when text-based architecture works and when visual-first is better.
Architecture docs, finally.
Turn system knowledge into current architecture docs fast, with linked views and one shared model.
No credit card required